We are starting an artificial intelligence explained video series with quick, short snippets of information on Explainability and Explainable AI. The first in the series is one on Shapley values - axioms, challenges, and how it applies to explainability of ML models.
Shapley values is an elegant attribution method from Cooperative Game Theory dating back to 1953. It was developed by Lloyd Shapley, who later won the Nobel Prize in Economics. It has been a really popular tool in economics, but has recently gained a lot of attention in explaining machine learning models. They are routinely applied to ML models in the lending industry, and are often used to create adverse action notices, i.e., explanations for a why loan request was denied.
What are Shapley values?
It is a fair and axiomatically unique method of attributing the gains from a cooperative game. Let’s unpack the Shapley Value attribution slowly.
- A cooperative game is one where a bunch of players collaborate to create some value. Think of a company where a bunch of employees come together and create some profit. The employees are the players and the profit is the gain.
- The game is specified such that we know the profit or payoff for any subset of the players.
- Shapley values are a certain distribution of this profit to the employees. Think of it as an algorithm to distribute bonuses. Notice that we would want such an algorithm to be fair, in that, the bonus must be commensurate with the employee’s contribution.
Unique under four simple axioms
The axioms can be intuitively understood as follows; interested readers may refer to this paper for formal definitions.
- [Efficiency] The bonuses add up to the total profit
- [Dummy] An employee that does not contribute gets no profit
- [Symmetry] Symmetric employees get equal profit
- [Linearity] Suppose the total profit comes from two separate departments. Then the bonus allocated to each employee should be the sum of the bonuses that they would receive from each of the departments individually.
No other method besides the Shapley values satisfies these properties. Isn’t that cool!
Shapley value algorithm
It is based on the concept of marginal contribution of an employee to the profit. Consider all possible orderings of employees. For each ordering, we introduce the employees in that order and note change in total profit at each step. The average marginal contribution of an employee across all orderings is the employee's Shapley value.
Suppose there are three employees and the order is Alice, Bob, Carol. Then we first add Alice to the company and note the increase in profit. This is the marginal contribution of Alice. Then we add Bob with Alice already present, and note the increase in profit. This is the marginal contribution of Bob, and so on. We repeat this for all possible orderings and compute the average marginal contribution. That’s it!
What's all this got to do to explainability of ML models?
A key question in explaining predictions made by ML models is: “Why did the model make this prediction?” For instance, “Why did the lending model deny this applicant?”, “Why is this text marked as negative sentiment?”, “Why was this image labeled as a dog?”
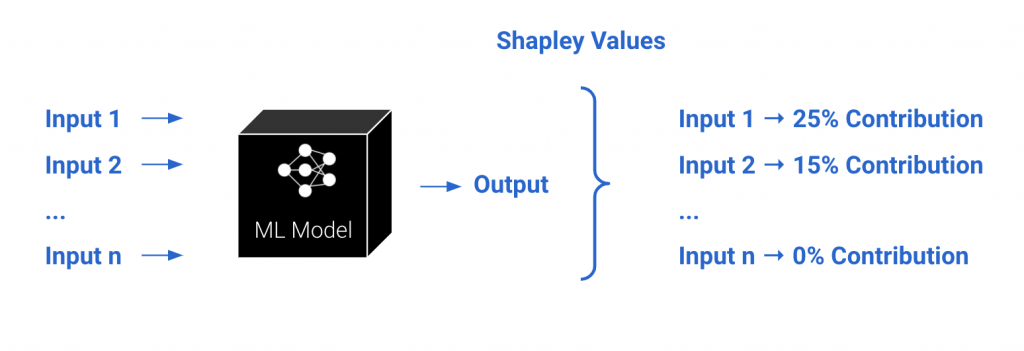
One way to answer this question is to quantify the importance of each input, also known as feature, in the prediction. It turns out that this is much like the bonus allocation problem that we just discussed. The prediction score is like the profit, and the features are like the employees. Quantifying the importance of features is like bonus allocation, which can be carried out using Shapley values!
Challenges in applying Shapley values to ML models
To compute Shapley values we need to measure the marginal contribution of a player, i.e., a feature in our case. Which means, we need to know the model’s prediction when a certain feature is absent. But how do we make a feature absent? This is the first challenge.
If we have a text input then making a word absent is easy, we simply drop it from the input sentence. But what about tabular input models? For instance how do we make the “income” feature absent. Different methods tackle this challenge in different ways.
Some methods make a feature absent by replacing it with a baseline value which may be a mean or median of the training distribution. Other methods model feature absence by sampling the feature from a certain distribution and take the expected prediction. Thus, to compute the prediction when the “income” feature is absent, one would draw various different values of “income” from a certain distribution and take the expected prediction. It’s sort of your estimate of the prediction when a certain feature is unknown. This is what is done by the popular SHAP algorithm.
But, again, different methods differ in what distribution they draw from. In the interest of time, I won’t go into the details but the choice of distribution is an important design choice that will have implications on the attribution you compute. Our recent preprint explores this choice in detail and provides guidance on how to pick the distribution.
Computation cost challenge
The second challenge is the computation cost of going through all possible orderings? With n features there ll be n! factorial orderings. With some algebra we can bring it down to 2^n model invocations. But this is still computationally expensive.
To combat this, most approaches use some form of sampling to make the computation tractable. Note that sampling introduces uncertainty and so it is important to quantify the uncertainty via confidence intervals over the attributions.
Conclusion
Finally, I would note that computing Shapley value only requires input-output access to the model. All we do is probe the model on a bunch of counterfactual inputs. In this sense, it is a black-box explanation method. Secondly, the method places no constraints on the type of model. The model function need not be smooth, differentiable or even continuous.