Before starting Fiddler, Krishna Gade was an engineering lead on Facebook’s NewsFeed, and his team was responsible for the feed ranking platform. This blog is a compilation of our experiences working on ML Operations at Facebook and Fiddler. Finally, we also propose a framework for ML Model Performance Management to solve some of the challenges.
ML Models are new software artifacts getting deployed at scale today. While training and deploying models is commoditized, monitoring and debugging ML is a hard problem. Model performance can degrade over time due to changes in input data post-deployment, therefore models require continuous monitoring to ensure their fidelity while in production. And while many existing monitoring tools provide real-time issue visibility, they are often insufficient to identify the root cause of issues within complex AI/ML systems.
State-of-the-art ML Operations
ML has played a huge role in the success of technology giants like Facebook, Amazon, Uber and Google, etc. All of these companies have built sophisticated ML Operations infrastructure to deliver product experiences for their users. For example, FBLearner is at the center of AI/ML at Facebook. It enables an ML Engineer to build Machine Learning pipelines, run lots of experiments, share model architectures and datasets with team members, and scale ML algorithms for billions of Facebook users worldwide. Since its inception, tons of models have been trained on FBLearner and these models answer billions of real-time queries to personalize News Feed, show relevant Ads, recommend Friend connections, etc. Similarly, Uber built Michelangelo, to manage, deploy, monitor ML pipelines at scale across their different products. And Google built TFX as a centralized ML platform for a variety of use-cases.
Model Monitoring
Let us take a closer look at how some of these platforms deal with Model Monitoring as part of their ML Operations. A typical ML Engineer working at these companies would get paged that an engagement metric e.g., “CLICKs” or “ORDERS” or “LIKES” is trending down. More often than not it translates to an ML model performance issue. A typical workflow to diagnose ML model performance at Facebook is to first check an internal monitoring system Unidash to see what is going on in production and then dive into Scuba to diagnose it further.
Scuba is a real-time analytics system that would store all the prediction logs and makes them available for slicing and dicing. It only supports FILTER and GROUP-BY queries and is very fast. ML Engineers would load up the Scuba dashboard for a given time window and start slicing data on a variety of attributes. For example, an engineer might check into questions like - Are the engagement metrics down for all types of NewsFeed posts? Are they down only within a particular country or region?
If I were on-call and I got a Model Performance alert that LIKES dropped by a stat-sig amount, the first thing I would do is to go into Scuba. I will zoom into LIKES last day and compare it with last week, and add filters like country, etc to find out which slice has the biggest deviation.
Types of Model Performance Issues
Most ML model performance issues occur due to data pipeline issues. For example, a developer could have introduced a bug in logging and that is sending bad feature data to the model or a piece of the data pipeline is broken because of a system error. Another set of issues can happen because ML models were not updated for a while and user behavior has changed. This usually results in the on-call contact opening a ticket for the model owner to retrain the model. Facebook also has continuous retraining of some models and these models needed to be tracked for reproducibility as they would get updated every few hours. ML Engineers would run lots of A/B tests and use Scuba metrics to figure out which model is performing the best before they bring that model dashboard for a launch review - an internal decision-making process to launch ML models to production.
Model Explainability
All of this infrastructure is backed by a fantastic set of explainability tools that help us debug models both during experimentation and production time frame. Some of these tools are integrated user-facing features like Why am I seeing this Post?.
Enterprise MLOps Challenges
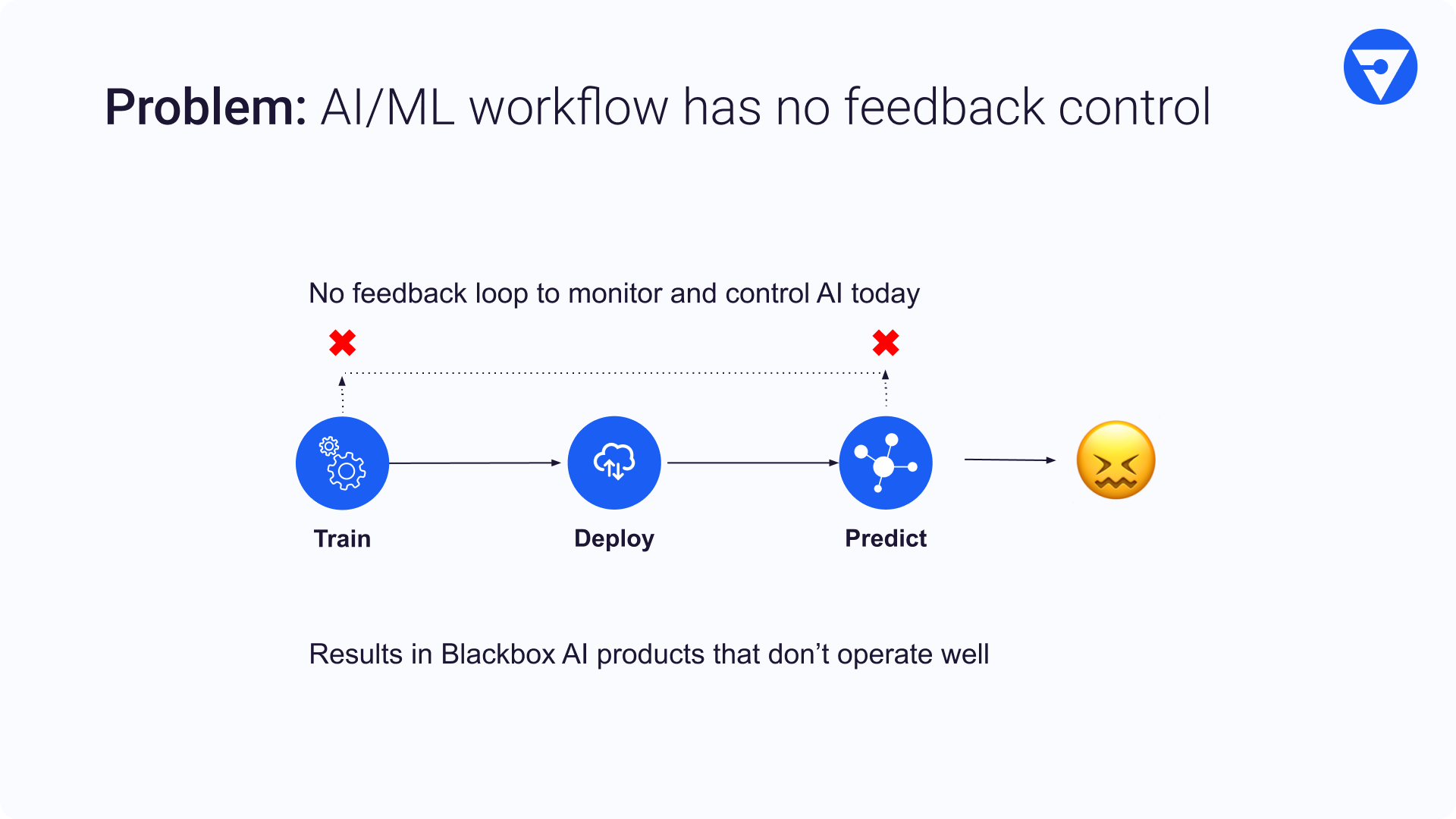
Outside of the FANG companies, many ML teams have a very simple workflow which tends to produce Black Box AI products that don’t operate well. One of the main problems with this workflow is that there is no feedback loop to monitor and control the performance of the ML models. We argue that this lack of feedback control makes production AI apps more error prone.
Growing Model Complexity
In the pursuit of more accurate models, the availability of computational resources and large datasets, ML teams are training more and more complex models.
- Variety - We’re seeing models serve a wide range of use-cases like anti-money laundering, job matching, clinical diagnosis, planetary surveillance.
- Versatility - Today’s models come in many forms and modalities (tabular, time series, text, image, video, audio) and often these modalities are mixed.
- Volume - With the availability of GPUs, TPUs, and large compute clusters, teams are able to train lots of these models in parallel.
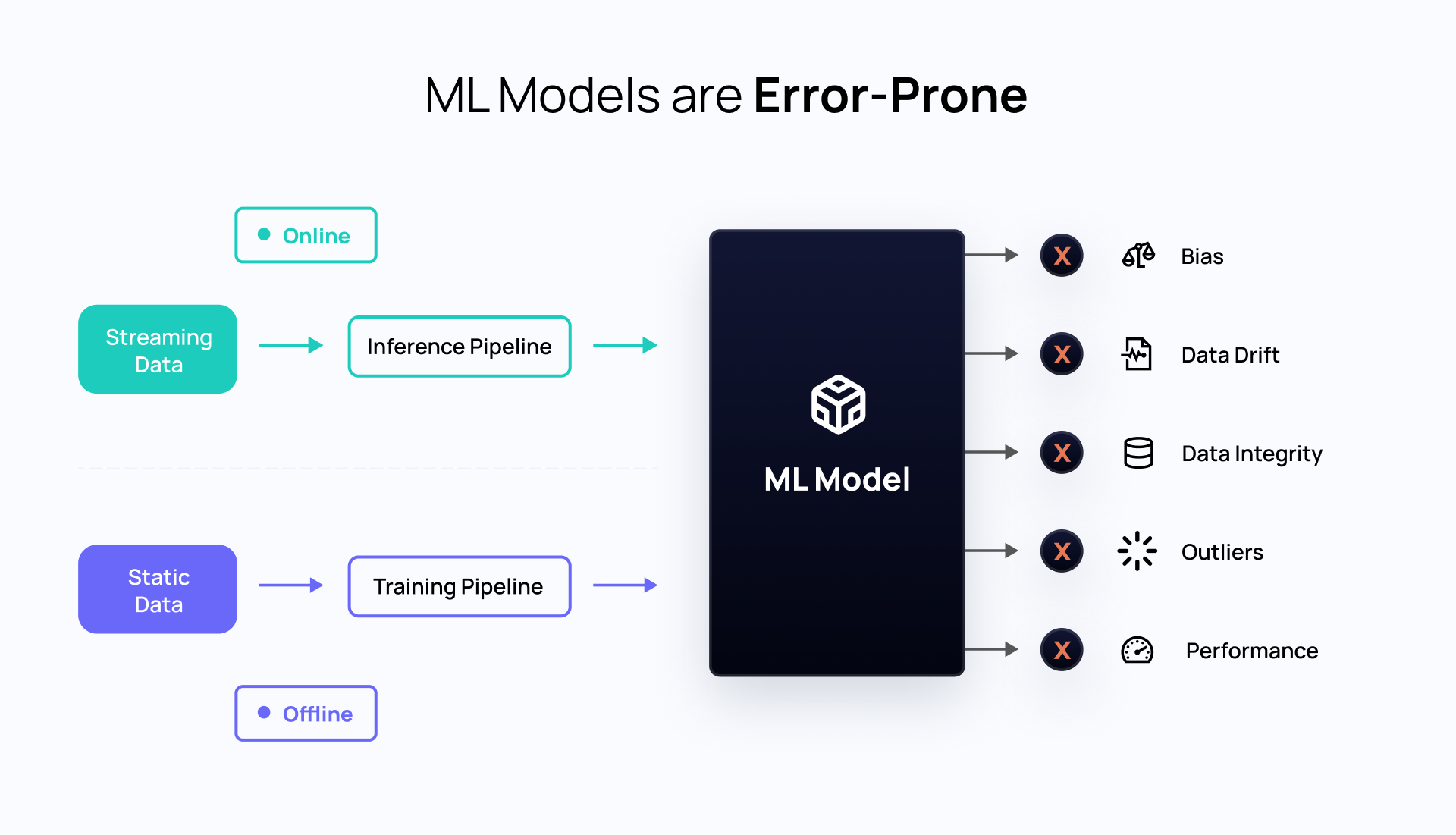
Offline/Online Discrepancies
There are 2 different pipelines for ML and this often results in model bugs in production.
- Training pipeline - Typically offline, works on static datasets.
- Inference pipeline - Typically online, works on streaming datasets.
A training pipeline (Offline) is typically batch oriented in the sense that it takes a curated snapshot of the data and trains a model. During this offline process, it is quite common to try a variety of model architectures, tune hyperparameters and come up with a set of candidate ML model experiments. Once a model is selected, it is then launched to the Inference pipeline (Online) where predictions are scored at scale on streaming datasets. Because of this split view, teams struggle with performance discrepancies of models between training and inference. Sometimes the metrics measured are totally different between the offline and online creating confusion amongst the various ML stakeholders.
Because of the increased model complexity, split world of Offline vs Online, and the lack of feedback loop, we are seeing ML Operations struggle with the following challenges.
- Inconsistent Performance - There can be large differences between how ML models perform offline and how they perform online.
- Loss of Control - Model developers have little control and visibility over adjusting model behavior on segments of data points where there is poor performance.
- Amplification of Bias - Not being able to validate training and test datasets for imbalances could amplify bias that violates corporate policy and result in customer mistrust.
- Lack of Debuggability - Inability to debug complex models could lead to low trust and model performance deterioration. It also prevents these models to be used in regulated industries such as Finance, Healthcare etc.
- Difficulty to Iterate - Challenges in tracking and comparing model behavior and performance across production versions makes it difficult to iterate on models.
A primer into Control Theory
To devise a solution for these challenges, we look into Control Theory, a branch of engineering that deals with governing and managing dynamical systems. There are 2 types of control systems.
- Open-loop systems
- Closed-loop systems
Open-loop System
An open-loop system is one where the input does not depend on the system output. Open-loop systems are typically used for simple processes that have well-defined input and output behaviors.
For example, a dishwasher is an open-loop system. The goal of a dishwasher is to clean dishes. Once the user sets the timer which controls the time (input) to clean, the dishwasher will run for that set time and produces clean dishes (output). The dishwasher works the same way and processes the input in the same manner no matter if the loaded dishes were clean or super dirty.
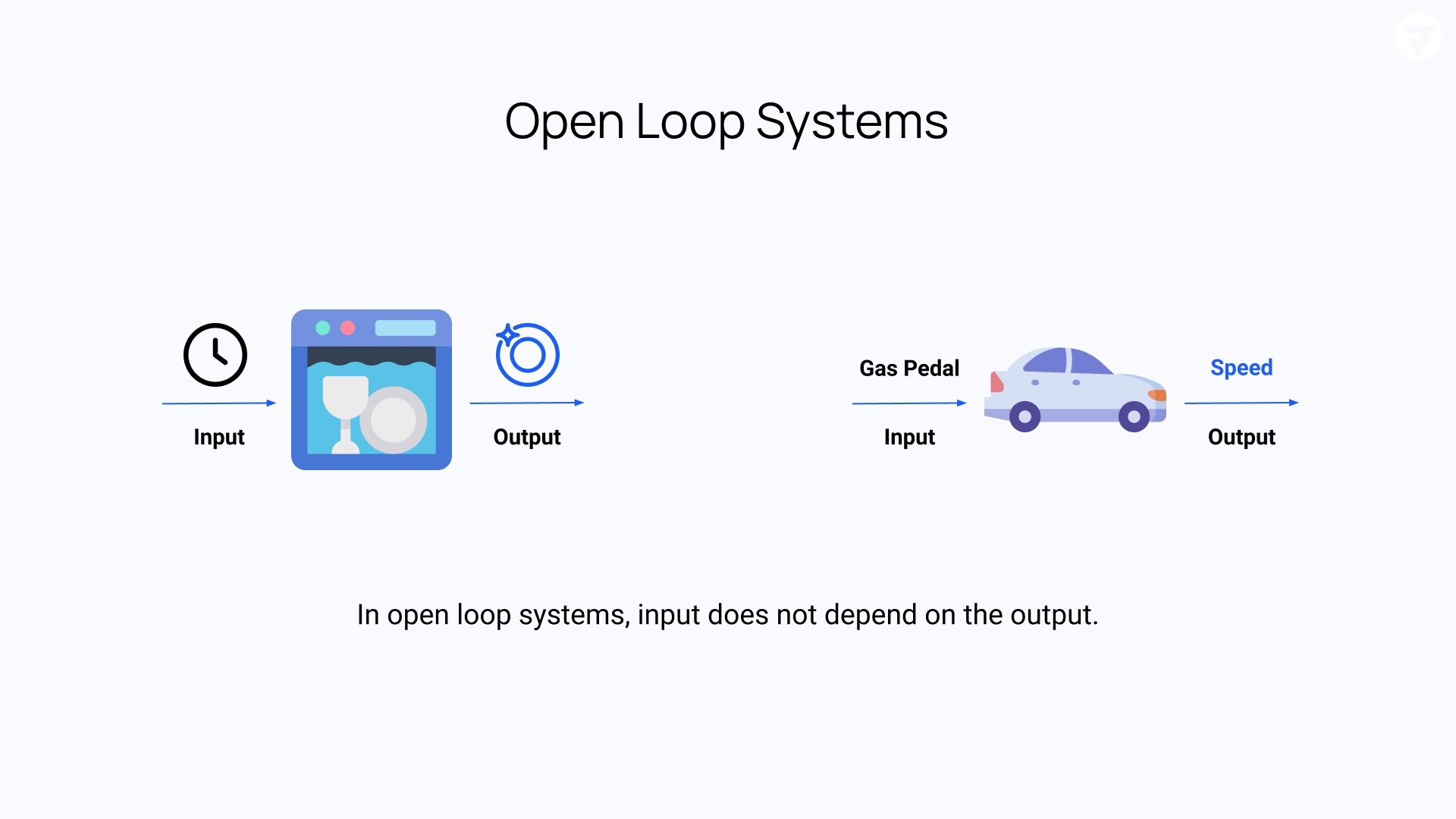
For a more complicated example, imagine trying to obtain a constant speed in a car without the benefit of the built-in automatic cruise control. To do this we can go to the gas pedal to depress it halfway down. The output here is the speed of the car and the input is the position of the gas pedal.
Problem with Open-loop Systems
Open-loop systems cannot deal with changes in the environment. For example, when our car enters a hill or a valley without us varying the speed by adjusting the gas pedal, the car will slow down or speed up. And the desired constant speed will not be maintained.
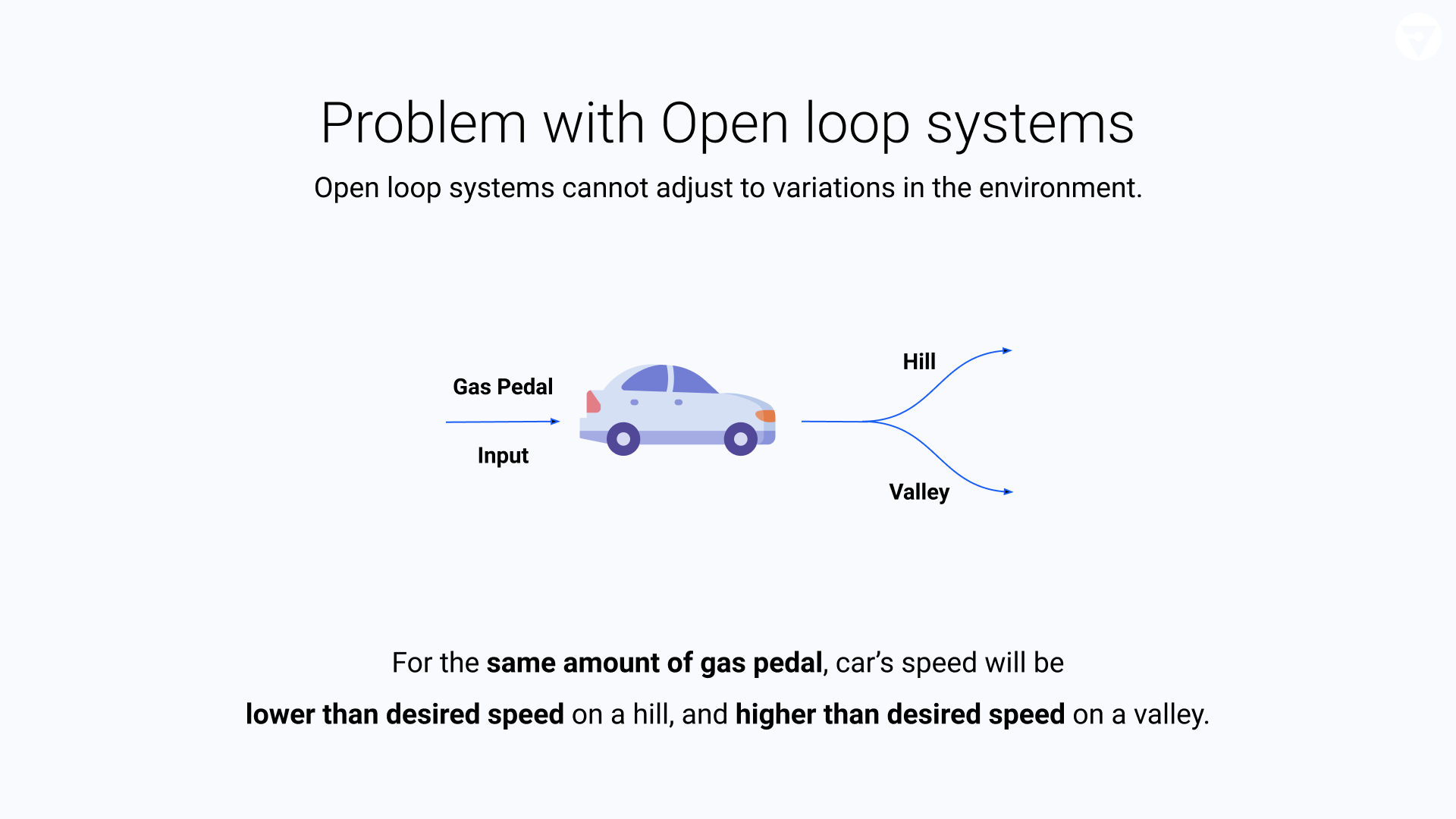
The primary drawback of an open-loop system is that it has no way to compensate for variations in the environment. To account for these changes we must vary the input to your system with respect to the output and this type of control system is called a closed-loop control system.
Closed-loop System
Closed-loop systems have a feedback loop that allows them to control new inputs based on the outputs. In the example of a car, a Speedometer measures the speed of the car and sends it to the Cruise Control that then figures how to adjust the gas pedal to achieve the desired speed.

Introducing ML Model Performance Management
We argue that ML Workflow is being operated today like an open-loop system, instead we need to create a feedback control loop and make it a closed-loop system to solve the ML Operations challenges. Therefore we propose a new framework below.
A Model Performance Management (MPM) framework is a centralized control system at the heart of the ML workflow that tracks and watches the model performance at all the stages and closes the ML feedback loop.
Key Characteristics of the MPM Framework
- During the training phase of the model, ML engineers can log their train and test datasets to the MPM framework and get insights into feature quality and any unintentional bias in the features.
- After the training of the model, the MPM framework can be used to validate models, explain performance and log all metrics. This is also a good place to keep track of any model reports that need to be generated for business or compliance or AI ethics stakeholders.
- When a new model is ready to be deployed, MPM can enable running tests against the prediction log of the old production model to perform Champion/Challenger testing.
- Once the model is launched to production, MPM serves as a monitoring tool to observe model performance, drift, bias, and alerts on error conditions.
- Upon receiving any alert notification, developers can leverage MPM to analyze, debug and root-cause model performance bugs.
- Finally, any new insights generated during Analysis can be then used to retrain a better model, thus closing the ML feedback loop.

It is important to note that an MPM Framework does not replace existing ML training, deployment, and serving systems. Instead, it sits at the heart of the ML workflow capturing all the model artifacts, training and production data, as well as model performance metrics.
Key Benefits of MPM
- Detect Train/Serving Skew - Features used to train and serve the models in the online and offline environments can differ. When this happens, the model will behave differently and needs to be debugged. By keeping the training data and prediction log in one place, MPM enables developers to detect these skews.
- Time Travel - Imagine a bank is using ML to approve loans, and they get a customer complaining about why a particular loan got denied. A risk operations user can log into MPM and go back in time to reproduce the prediction along with the explanation.
Conclusion
In this blog, we reviewed the state-of-the-art ML Operations tools, challenges with Enterprise ML Operations, and how a new framework like Model Performance Management (MPM) can address them. In future blogs, we will look more deeply into the MPM framework we’re building at Fiddler and how things work internally.
